Inhaltsübersicht
Wenn Sie studieren oder mit vielen Bildern und PDFs arbeiten, haben Sie sicher schon einmal das Bedürfnis verspürt, Text aus einem Bild oder einem Dokument zu extrahieren.
Glücklicherweise ist dies mit der Textextraktion möglich. Und es gibt mehrere Tools, die Sie dafür verwenden können. gImageReader ist eines der vielen Tools. Es ist kostenlos und funktioniert sowohl mit Bilddateien als auch mit PDF-Dokumenten.
Schauen wir uns gImageReader im Detail an und erfahren, wie Sie damit Text aus Bildern und PDFs extrahieren können.
Was ist gImageReader?
gImageReader ist eine Anwendung, mit der Sie Text aus Bildern und PDFs unter Linux extrahieren können. Es handelt sich im Wesentlichen um eine grafische Benutzeroberfläche oder ein Front-End für die Tesseract OCR-Engine, eine von Hewlett-Packard entwickelte Open-Source-Engine, die als eine der besten verfügbaren OCR-Engines gilt.
Mit gImageReader können Sie mit ein paar einfachen Klicks Text aus Bildern oder PDF-Dokumenten extrahieren. Anschließend können Sie den extrahierten Text zur weiteren Verwendung in eine Text- oder PDF-Datei exportieren.
Eigenschaften von gImageReader
gImageReader verfügt über die folgenden Funktionen:
- Importieren Sie PDF-Dokumente und Bilder aus verschiedenen Quellen (Festplatte, Scangeräte, Zwischenablage und Bildschirmfotos)
- Stapelverarbeitung von Bildern oder Dokumenten, d. h. Extraktion von Text aus mehreren Bildern oder Dokumenten auf einmal
- Erkennen von Textfragmenten als reiner Text oder hOCR-Dokumente
- Eingebaute Rechtschreibprüfung
- Automatische Erkennung von Textbereichen
- Einfache Bild-/Dokumentenbearbeitung
- Speichern der Ausgabe als Textdatei
So installieren Sie gImageReader unter Linux
gImageReader ist für die meisten gängigen Linux-Distributionen verfügbar. Bevor Sie jedoch mit der Installation fortfahren, müssen Sie die Tesseract OCR-Engine auf Ihrem System installieren.
Dazu öffnen Sie den Software-Manager auf Ihrem System und suchen nach tesseract. Wenn Sie eine Liste von Ergebnissen erhalten, installieren Sie die Pakete tesseract-ocr und tesseract-ocr-eng. Sie können auch einen Kommandozeilen-Paketmanager verwenden, um die Pakete zu installieren, wenn Sie mit dem Terminal besser vertraut sind.
Danach lesen Sie bitte die Installationsanweisungen in den folgenden Abschnitten, um gImageReader auf Ihrem Computer zu installieren.
Wenn Sie unter Debian oder Ubuntu arbeiten, öffnen Sie das Terminal und führen Sie die folgenden Befehle aus, um gImageReader zu installieren:
sudo add-apt-repository ppa:sandromani/gimagereadersudo apt-get updatesudo apt install gimagereader
Unter Fedora, CentOS oder Red Hat Enterprise Linux (RHEL):
sudo dnf install gimagereader-qt
Unter Arch Linux oder Manjaro:
sudo pacman -S gimagereader
openSUSE-Benutzer können gImageReader wie folgt installieren:
sudo zypper install gimagereader
Falls Sie eine andere Linux-Distribution verwenden, können Sie gImageReader aus dem Quellcode bauen, indem Sie den Anweisungen auf gImageReader’s GitHub folgen.
Wie man gImageReader unter Linux verwendet
gImageReader ist recht einfach zu bedienen und funktioniert mit allen Arten von Bilddateien sowie PDF-Dokumenten. Folgen Sie den nachstehenden Anweisungen, um Text aus Bildern oder PDFs unter Linux zu extrahieren.
Öffnen Sie das Anwendungsmenü, suchen Sie nach gImageReader, und starten Sie die Anwendung. Klicken Sie im gImageReader-Fenster auf die Schaltfläche Maximieren, um es in der Vollbildansicht zu öffnen.
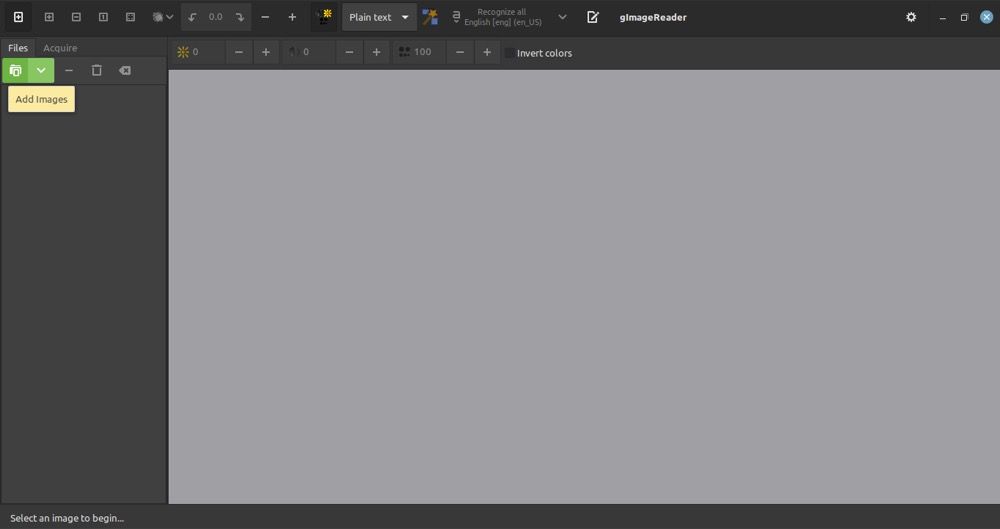
Klicken Sie nun auf die Schaltfläche Bilder hinzufügen im linken Bereich unter der Symbolleiste und verwenden Sie den Dateibrowser, um das/die Bild(er) oder PDF(s) auszuwählen, aus denen Sie Text extrahieren möchten.
Klicken Sie auf Ok, um das/die Bild(er) oder PDF(s) in gImageReader zu importieren. Oder wenn Sie Text aus dem auf dem Bildschirm angezeigten Inhalt extrahieren möchten, klicken Sie auf das Dropdown-Menü neben der Schaltfläche Bilder hinzufügen und wählen Sie Screenshot machen. gImageReader macht einen Screenshot vom Inhalt des Bildschirms.
Wenn Sie das Bild zu gImageReader hinzugefügt haben, klicken Sie auf die Schaltfläche Ausgabebereich umschalten (die Schaltfläche mit dem Notizblocksymbol), um den Ausgabebereich zu öffnen. Hier wird der Text angezeigt, den Sie aus Bildern oder PDFs extrahieren.
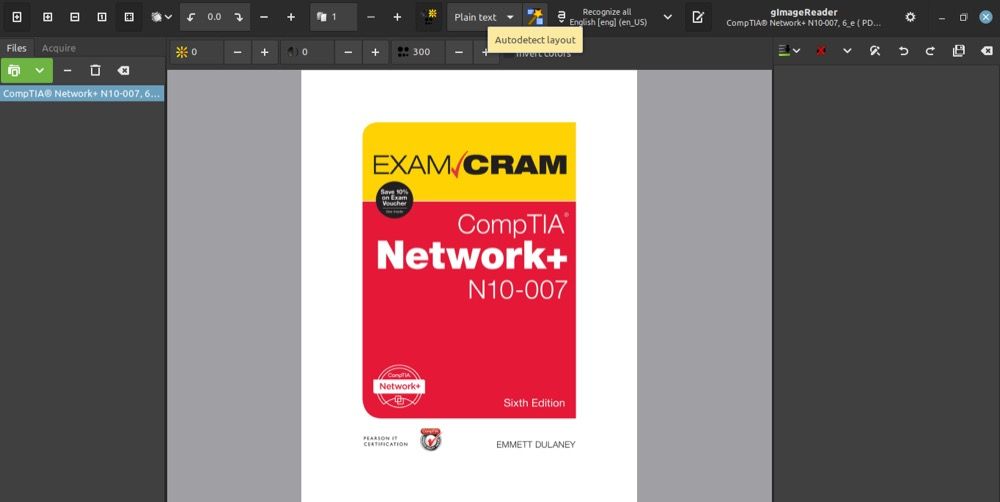
Je nachdem, wie Sie vorgehen möchten, haben Sie nun die Möglichkeit, den Text im Bild oder PDF automatisch oder manuell zu erkennen. Um dies automatisch zu tun, klicken Sie auf die Schaltfläche "Layout automatisch erkennen". Daraufhin werden alle Textblöcke in dem ausgewählten Bild oder PDF-Dokument markiert.
Tippen Sie anschließend auf Auswahl erkennen > Aktuelle Seite, um die Textextraktion zu starten.
Alternativ können Sie den Text auch manuell auswählen, indem Sie den Mauszeiger über den zu extrahierenden Text bewegen und mit dem Fadenkreuz einen Rahmen um den Bereich ziehen, aus dem Sie den Text extrahieren möchten. Klicken Sie dann auf die Schaltfläche "Auswahl erkennen", um fortzufahren.

Wenn es sich um ein PDF-Dokument handelt und Sie Text von verschiedenen Seiten extrahieren möchten, tippen Sie auf die Schaltfläche Plus ( ), um die Seiten umzublättern.
Um zurückzugehen, klicken Sie auf die Schaltfläche Minus (-). Wählen Sie dann den Text aus, den Sie extrahieren möchten, und klicken Sie auf die Schaltfläche "Auswahl erkennen", um ihn zu extrahieren.
Obwohl selten, kann es vorkommen, dass gImageReader den extrahierten Text in einer anderen Sprache als Englisch zurückgibt. Wenn dies der Fall ist, tippen Sie einfach auf die Dropdown-Schaltfläche neben der Schaltfläche Auswahl erkennen und wählen Sie eine der englischen Optionen.
Um den extrahierten Text zu speichern, klicken Sie auf die Schaltfläche Ausgabe speichern. Daraufhin wird das Fenster Speichern angezeigt. Geben Sie hier einen Namen für die Datei ein und klicken Sie auf Ok.
Was können Sie sonst noch mit gImageReader tun?
Wie bereits erwähnt, bietet gImageReader auch die Möglichkeit, bestimmte Aspekte der importierten Bilder oder Dokumente zu ändern, z. B. ihre Helligkeit, ihren Kontrast und ihre Auflösung. Darüber hinaus können Sie bei Bedarf auch Farben invertieren oder die Bilder oder Dokumente drehen.
Die meisten dieser Optionen können sich als nützlich erweisen, wenn der Text in einem Bild oder Dokument für gImageReader nicht lesbar ist und daher das Tool daran hindert, den Text zu erkennen.
Um auf eine dieser Bearbeitungsoptionen zuzugreifen, klicken Sie auf die Schaltfläche Bildsteuerung, die eine Minisymbolleiste unterhalb der Hauptsymbolleiste einblendet. Wählen Sie hier die entsprechenden Schaltflächen aus, um die gewünschte Bearbeitung des Bildes oder Dokuments vorzunehmen.
Textextraktion unter Linux leicht gemacht mit gImageReader
Für die Textextraktion ist oft das richtige Tool erforderlich: ein Tool mit einer zuverlässigen und präzisen OCR-Engine, die es ermöglicht, Text in einem Bild oder Dokument effektiv zu erkennen, so dass Sie ihn effizient und problemlos extrahieren können.
gImageReader erreicht dies dank der Tesseract OCR-Engine, die es im Hintergrund verwendet, auf hervorragende Weise. In Anbetracht seiner Benutzerfreundlichkeit ist gImageReader zweifelsohne eines der besten Textextraktionsprogramme, die für Linux verfügbar sind.
Wenn Sie eine einfachere Lösung suchen, können Sie auch TextSnatcher ausprobieren, das schnell und ziemlich einfach zu bedienen ist.